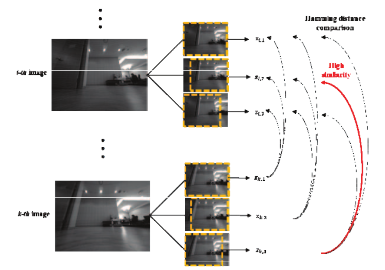
Unstructured off-road environments present new challenges for autonomous driving. This project focuses on developing a perception system for unmanned vehicles in off-road scenarios.
Off-road environments have the following characteristics:
- Ambiguous definition of traversable space: In off-road scenarios, driving intelligence must comprehensively analyze spatial and visual data to accurately distinguish traversable spaces.
- Environmental changes according to seasons: Even in the same area, the environment can appear completely different, such as dense foliage in summer versus snow-covered landscapes in winter.
We successfully developed a perception system to support the safe operation of vehicles in off-road environments, completing unmanned exploration experiments in mountainous terrain.
]]>